Abstract
We present Rosetta, a composable native multimodal pretraining framework for integrating understanding and generation without catastrophic forgetting. Unlike standard MoE and structurally partitioned MoT, which suffer severe gradient conflicts and representation overwriting when continuous generative objectives are added, Rosetta preserves foundational knowledge in global shared experts while expanding through plug-and-play modality experts.
To guarantee non-destructive composition with zero additional memory overhead, we propose Momentum-Anchored Orthogonal Projection (MAOP), which repurposes optimizer momentum as an implicit semantic anchor to selectively neutralize conflicting gradient components from new modalities. Under strict parameter parity with MoE and MoT baselines in the Transfusion framework, extensive experiments show that Rosetta maintains language and visual understanding ability while delivering superior image generation and cross-modal synergy.
Architecture
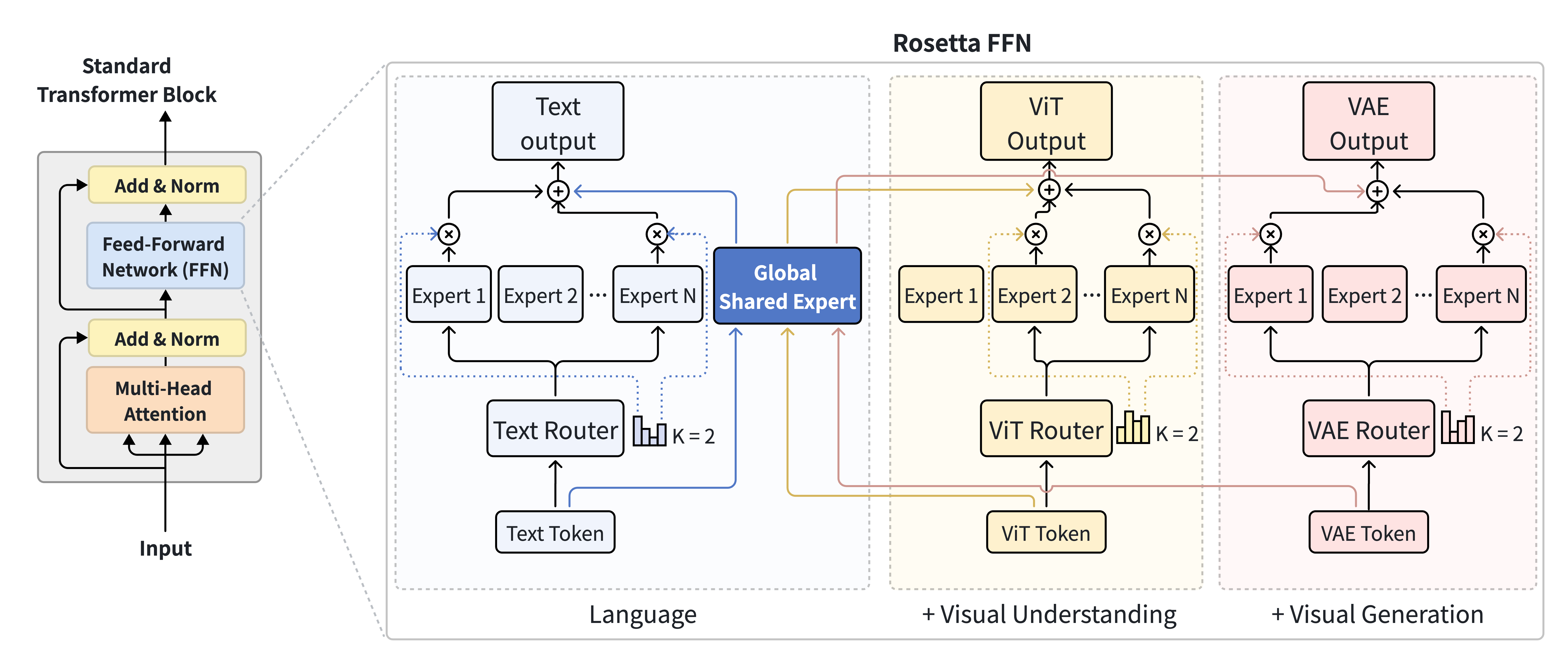
Figure 2. Rosetta FFN. Three mechanisms enable non-destructive modality expansion: (1) Unified Attention, globally shared QKV projections preserve dense cross-modal interactions. (2) Composable FFN, modality-specific plug-and-play experts (Text / ViT / VAE) are bridged by a single Global Shared Expert that anchors foundational knowledge. (3) Conflict-Free Optimization (MAOP), surgically neutralizes destructive gradients with zero memory overhead.
Main Results
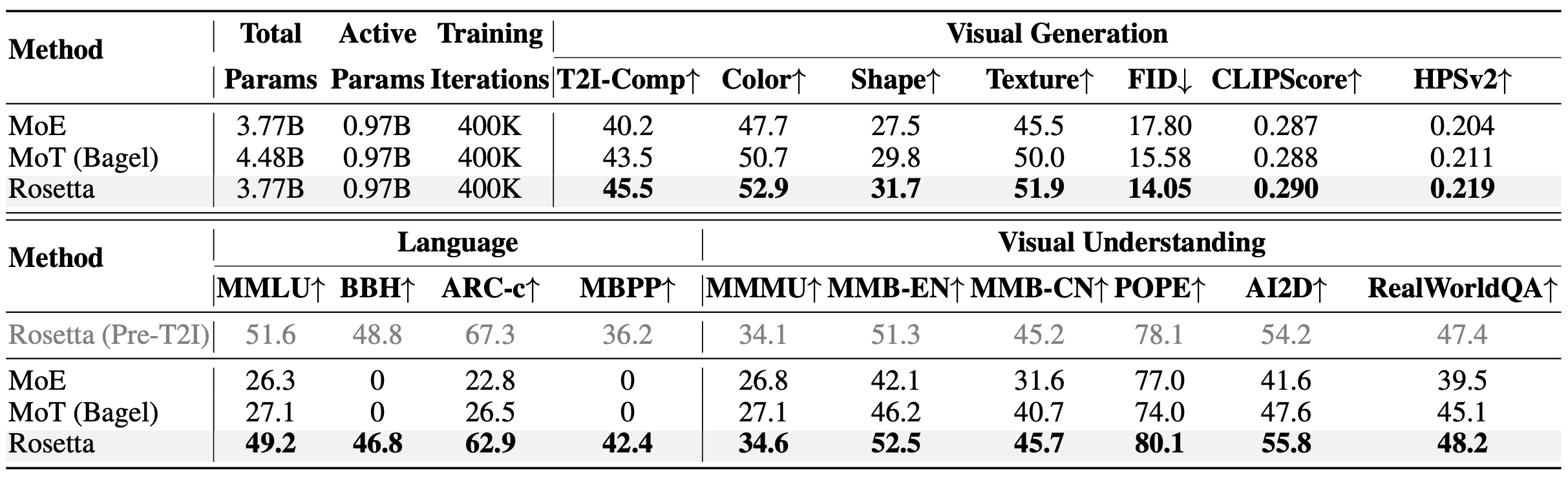
Table 1. Comprehensive Performance Evaluations. All methods are evaluated in their raw foundation state after the full multimodal pretraining phase (LM+MMU+T2I) under identical training constraints, strictly without any downstream instruction tuning. Rosetta fundamentally overcomes the catastrophic forgetting existing in MoE and MoT, achieving the best across all three capability domains (Language, Visual Understanding, and Visual Generation). The gray row Rosetta (Pre-T2I) represents the understanding performance of Rosetta prior integrating T2I. (Bold: Best)
Training Dynamics
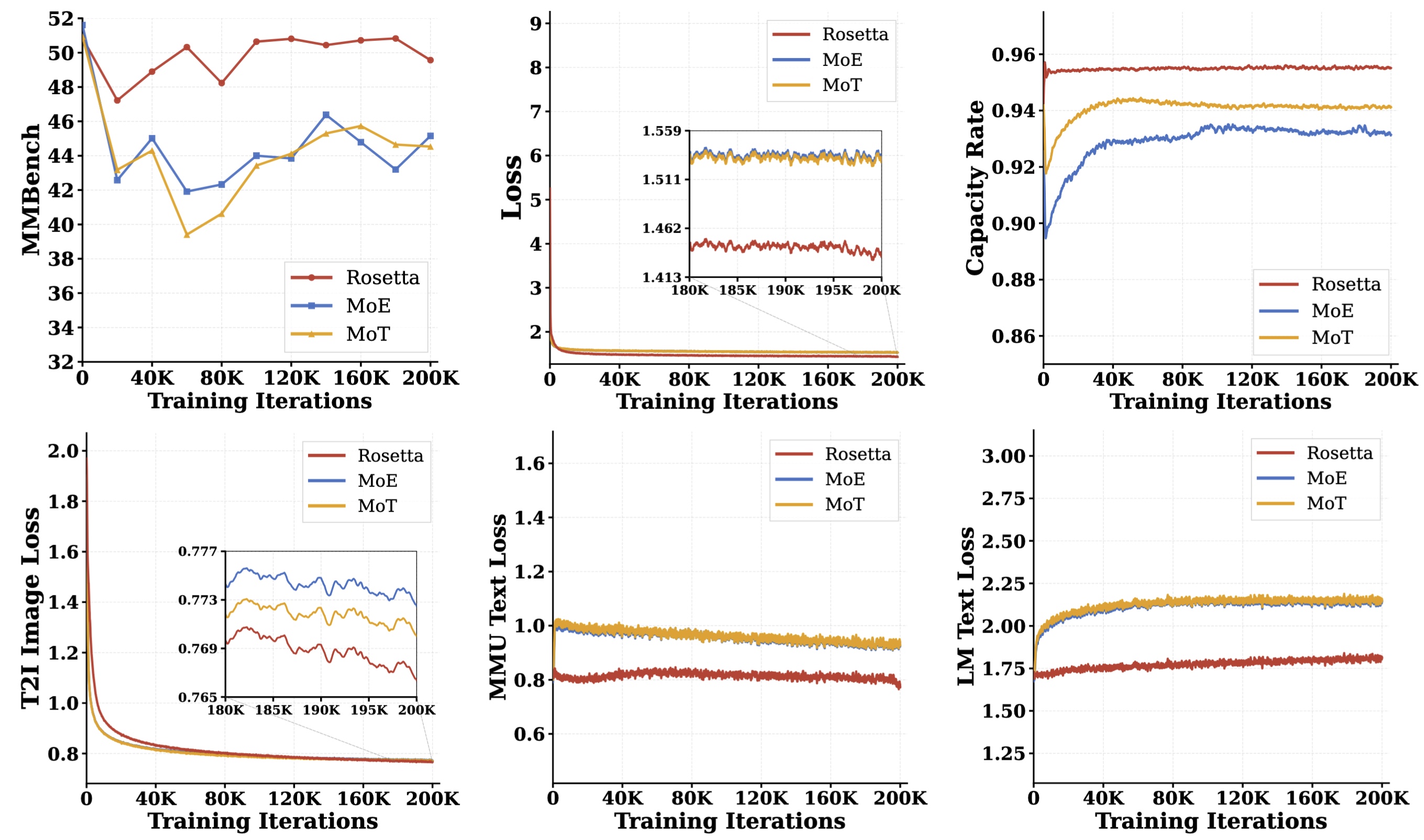
Figure 3. Comprehensive Training Dynamics. Evaluated over a 200K-step generative expansion. (1) Overall Dynamics (Top Row): Rosetta averts the irreversible MMBench degradation in MoE and MoT baselines, maintaining a synergistic upward trajectory (Left). It also achieves a deeper optimization bound (Center) and near-optimal capacity rate (i.e., ratio of successfully routed, non-dropped tokens; ~0.95, Right). (2) Task-Specific Losses (Bottom Row): Rosetta accelerates T2I convergence (Left) and neutralizes cross-modal gradient interference, guaranteeing strictly lower and stable trajectories for both visual (Center) and language understanding (Right).
Deep Analysis: Unmasking the Collapse
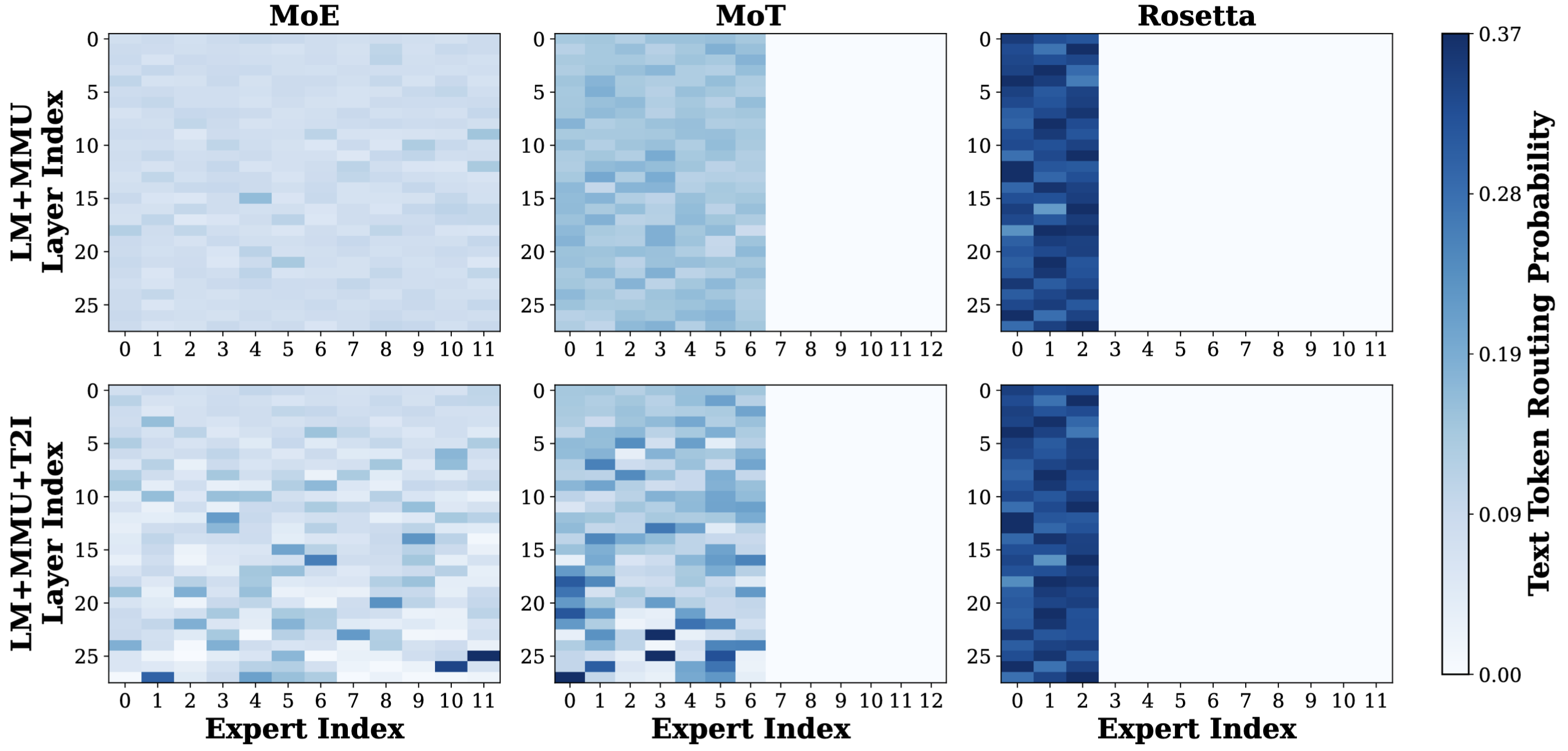
Figure 4. Routing Distribution Heatmaps During Generative Expansion. We visualize the routing probabilities of Text tokens across experts during MMLU inference. Top Row: Checkpoints under the LM+MMU configuration (iteration 55K in Fig. 1). Bottom Row: Checkpoints upon integrating 30K steps of T2I training (iteration 85K in Fig. 1). Both MoE and MoT exhibit significant distribution shifts, indicating severe cross-modal interference. In contrast, Rosetta maintains nearly identical routing distribution, successfully preserving pre-established language capabilities.
Qualitative Generation

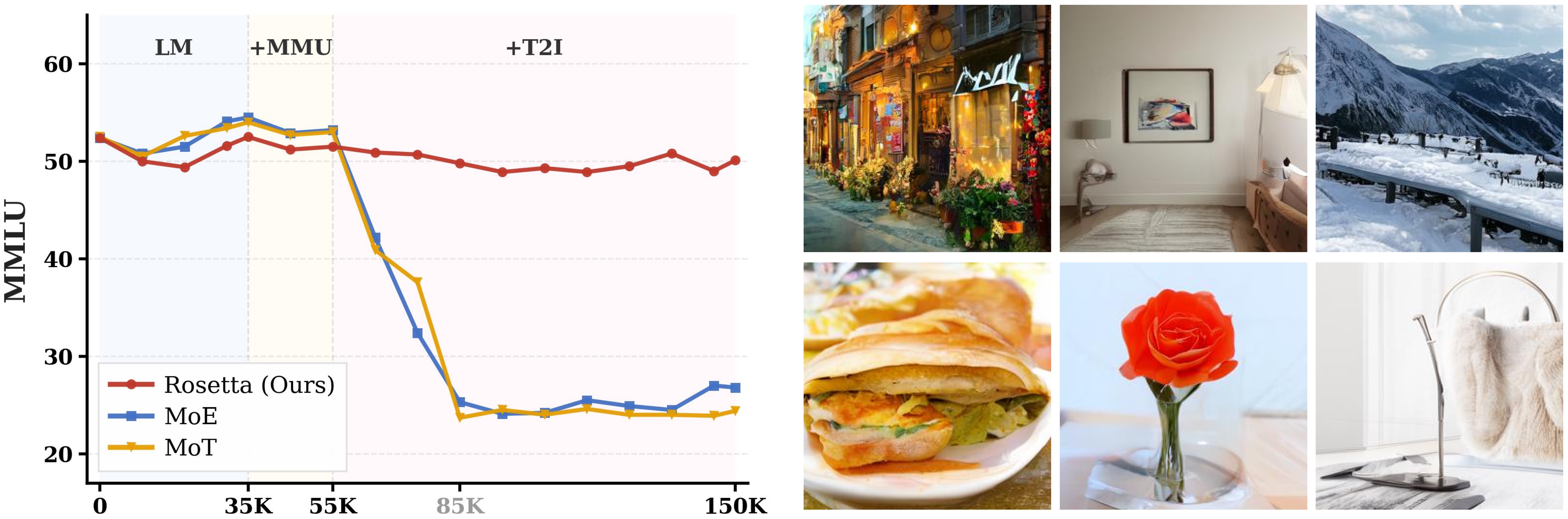
Figure 5. Qualitative Comparisons. Standard MoE suffers semantic drift (e.g., bird to bottle) and MoT exhibits structural distortions (e.g., broken lamp). In contrast, Rosetta leverages cross-modal synergy to synthesize high-fidelity images with precise spatial geometry and prompt adherence.
Citation (Coming Soon)
@article{liu2026rosetta,
title={Rosetta: Composable Native Multimodal Pretraining},
author={Liu, Xiangyue and Zhang, Zijian and Yang, Miles and Zhong, Zhao and Bo, Liefeng and Tan, Ping},
year={2026}
}